Variantie is een statistische maatstaf die ons vertelt hoe goed gegevens rond het gemiddelde zijn verdeeld . Het is hetzelfde als meten hoe “verspreid” de gegevens zijn ten opzichte van de gemiddelde waarde.
Stel je voor dat je een lijst met getallen hebt, zoals scores op een toets. Variantie helpt u te begrijpen hoe verschillend deze scores van elkaar zijn . Als de scores heel dicht bij elkaar liggen, is de variantie laag. Maar als er veel verschillen zijn tussen de scores, zal de variantie groot zijn.
Over het algemeen is variantie een nuttig hulpmiddel om de spreiding van gegevens in een reeks waarden te begrijpen. Als de variantie hoog is, betekent dit dat de gegevens meer verspreid zijn, terwijl als deze laag is, de gegevens dichter bij elkaar liggen.
Hoe wordt de kloof berekend?
Om de variantie te berekenen, moet je een paar wiskundige stappen ondernemen, maar maak je geen zorgen: het is eenvoudiger dan het lijkt. Eerst moet u het gemiddelde of het gemiddelde van de gegevens berekenen. Trek vervolgens elk stukje gegevens af van het gemiddelde en kwadraat elk verschil. Vervolgens telt u al deze vierkanten bij elkaar op en deelt u deze door de hoeveelheid gegevens. Het is de variantie.
Om dit wat beter te begrijpen, bekijken we hieronder een voorbeeld van het berekenen van de variantie:
Stap 1: Haal de gegevens op
Stel dat je de volgende gegevens hebt: 5, 7, 9, 11, 13. Dit zijn de waarden uit een steekproef van gegevens waarvan je de variantie wilt berekenen.
Stap 2: Bereken het gemiddelde
Tel alle waarden bij elkaar op en deel door de totale hoeveelheid gegevens om het gemiddelde te krijgen:
Gemiddeld = (5 + 7 + 9 + 11 + 13) ÷ 5 = 45 ÷ 5 = 9
Het gemiddelde van de gegevens is 9.
Stap 3: Trek het gemiddelde van elk gegevenspunt af
Trek het in de vorige stap verkregen gemiddelde af van elk gegevensitem in de lijst:
5 – 9 = -4
7 – 9 = -2
9 – 9 = 0
11 – 9 = 2
13 – 9 = 4
Stap 4: Vier elk verschil
Vier elk van de verschillen verkregen in de vorige stap:
(-4) 2 = 16
(-2) 2 = 4
0 2 = 0
2 2 = 4
4 2 = 16
Stap 5: Voeg de vierkanten van de verschillen toe
Tel alle resultaten op die u in de vorige stap hebt verkregen:
16 + 4 + 0 + 4 + 16 = 40
Stap 6: Deel door de hoeveelheid gegevens
Deel de som van de kwadraten van de verschillen door de totale hoeveelheid gegevens (in dit geval 5):
Afwijking = 40 ÷ 5 = 8
De variantie van de gegevens is 8 .
Wat is de formule voor variantie?
Voordat we dit punt analyseren, is het belangrijk om te vermelden dat variantie van groot belang is voor statistieken. Ondanks dat het een vrij eenvoudige maatregel is, levert het interessante informatie op op basis van een specifieke variabele.
De meeteenheid is altijd degene die overeenkomt met de gegevens, maar dan in het kwadraat. Bovendien moet worden opgemerkt dat de variantie altijd gelijk is aan of groter is dan nul. Dit komt omdat de residuen altijd in het kwadraat zijn, dus in wiskundige termen is het onmogelijk dat er een negatieve variantie is.
Met dit in gedachten laten we u hieronder de variantieformule zien:
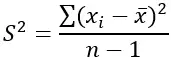
S2 = opening
x i = datasetterm
X̄ = monstermeting
∑ = som
n = steekproefomvang
Wat is hoge en lage variantie?
Variantie wordt als hoog beschouwd als de gegevens in een statistische steekproef of populatie zeldzaam zijn en ver van het gemiddelde liggen . Dit betekent dat individuele waarden in de gegevens wijd verspreid zijn en dat er een grote variabiliteit in de gegevens bestaat.
De variantie wordt daarentegen als laag beschouwd als de gegevens in een steekproef of populatie dichter bij het gemiddelde liggen en er weinig spreiding is tussen individuele waarden. Dit impliceert dat de gegevens consistenter zijn en minder variabel zijn.
Wat zijn de belangrijkste toepassingen van variantie?
Variantie is een statistische maatstaf die op verschillende gebieden veel wordt gebruikt vanwege het vermogen om de spreiding of variabiliteit van gegevens in een steekproef te beoordelen. Enkele van de belangrijkste toepassingen van variantie zijn:
In beschrijvende statistieken – om de spreiding van gegevens in een steekproef te beschrijven, om te helpen begrijpen hoe individuele waarden afwijken van het gemiddelde en hoe ze binnen de steekproef zijn verdeeld.
In inferentiële statistieken : het schatten van de variabiliteit van gegevens in een populatie op basis van een steekproef, waardoor conclusies kunnen worden getrokken over de populatie als geheel.
In de financiële sector : bij de analyse van beleggingsrisico en -rendement, waarbij een hogere variantie een hoger risico aangeeft en een lagere variantie een lager risico in een beleggingsportefeuille.
In wetenschappelijk onderzoek – Analyseer de variabiliteit van gegevens in wetenschappelijke studies, zoals medisch onderzoek, biologie, psychologie en andere disciplines, om de variabiliteit van resultaten en de consistentie van gegevens te begrijpen.
Bij de controle van de proceskwaliteit : bij de kwaliteitscontrole van industriële processen om de variabiliteit van de vervaardigde producten of diensten te meten, waardoor het mogelijk wordt problemen met de consistentie en kwaliteit van het proces te identificeren.
In econometrie : bij het modelleren en analyseren van economische gegevens om de variabiliteit van economische variabelen te begrijpen en de betrouwbaarheid van econometrische modellen te evalueren.
Wat is de betekenis van variantie?
Variantie is belangrijk omdat u hierdoor inzicht krijgt in de variabiliteit van gegevens in een steekproef . Als de variantie hoog is, betekent dit dat de gegevens schaars zijn en dat er veel variabiliteit is. Dit is relevant voor het nemen van weloverwogen beslissingen op gebieden als investeringen, risicobeheer en data-analyse.
Bovendien helpt variantie u de consistentie van gegevens in een steekproef of populatie te begrijpen. Een lage variantie geeft aan dat de gegevens consistent zijn en weinig variabiliteit hebben, terwijl een hoge variantie aangeeft dat de gegevens minder consistent zijn en meer variabiliteit hebben.
Zijn standaarddeviatie en variantie hetzelfde?
Standaarddeviatie en variantie zijn twee gerelateerde statistische maatstaven die de spreiding of variabiliteit van gegevens in een steekproef of populatie beschrijven . Het belangrijkste verschil tussen beide is de meeteenheid en de interpretatie van de resultaten.
Variantie is een maatstaf die de spreiding van gegevens ten opzichte van het gemiddelde weergeeft, berekend als de som van de kwadraten van de afwijkingen van individuele waarden ten opzichte van het gemiddelde, gedeeld door het totale aantal gegevens.
Het wordt berekend door de verschillen tussen elke waarde en het gemiddelde te kwadrateren, ze bij elkaar op te tellen en ze te delen door de steekproef- of populatiegrootte. De variantie wordt uitgedrukt in kwadratische eenheden en kan moeilijk direct te interpreteren zijn, omdat deze zich op een andere schaal bevindt dan de oorspronkelijke gegevens.
Aan de andere kant is de standaarddeviatie niets meer dan de vierkantswortel van de variantie . Het wordt berekend als de positieve vierkantswortel van de variantie. De standaardafwijking wordt uitgedrukt in dezelfde eenheden als de originele gegevens en is een meer intuïtieve maatstaf voor de gegevensspreiding.
Een hogere standaardafwijking duidt op een grotere spreiding of variabiliteit in de gegevens, terwijl een lagere standaardafwijking duidt op minder spreiding of variabiliteit.
Gat voor gegroepeerde gegevens
Variantie voor gegroepeerde gegevens verwijst naar de berekening van de variabiliteit of spreiding van gegevens die zijn gegroepeerd in intervallen of klassen . In plaats van individuele gegevens te hebben, zoals in het geval van variantie voor niet-gegroepeerde gegevens, heb je bereiken of intervallen waarin de gegevens vallen.
Het berekenen van de variantie voor gegroepeerde gegevens gebeurt met een iets andere formule. Eerst wordt het middelpunt van elk interval berekend, wat het gemiddelde is van de onder- en bovengrens van elk interval. Vervolgens wordt het gewogen gemiddelde van de middelpunten berekend, waarbij de relatieve of absolute frequenties van de intervallen als gewichten worden gebruikt.
Uit dit gewogen gemiddelde wordt de variantie berekend volgens dezelfde formule als voor niet-gegroepeerde gegevens , dat wil zeggen als het gemiddelde van de kwadraten van de verschillen tussen de individuele waarden en het gewogen gemiddelde.
Gegroepeerde gegevensvariantie is handig bij het werken met gegevenssets die worden gepresenteerd als intervallen of klassen, zoals demografische gegevens, economische gegevens of andere soorten gegevens die in categorieën of bereiken zijn gegroepeerd.
Variantie-eigenschappen
Variantie is een statistische maatstaf die verschillende belangrijke eigenschappen heeft. Enkele van de belangrijkste eigenschappen van variantie zijn:
- Het is altijd een niet-negatieve waarde , omdat deze wordt gedefinieerd als het gemiddelde van de kwadraten van de verschillen tussen de individuele gegevens en het gemiddelde.
- Het is gevoelig voor extreme of uitschieters in de gegevens , omdat het het kwadraat van de verschillen is.
- Het heeft eenheden in het kwadraat , wat impliceert dat het in dezelfde eenheid in het kwadraat zit als de originele gegevens.
- Het kan worden beïnvloed door uitschieters of extreme gegevens, waardoor het een niet-robuuste maatstaf voor de variabiliteit van gegevens kan worden.
- Als de gegevens onafhankelijk zijn en niet met elkaar gecorreleerd, is de variantie van de som van twee sets gegevens gelijk aan de som van de varianties van de twee sets gegevens .
Voorbeelden van afwijkingen
Nu we het concept variantie en het belang ervan begrijpen, gaan we naar een praktisch voorbeeld kijken om beter te begrijpen hoe het werkt.
Stel dat we de volgende gegevens hebben over het economische resultaat van een bedrijf in miljoenen dollars over de afgelopen vijf jaar: 8, 12, 6, -4, 10. We willen de variantie van deze gegevensset berekenen met behulp van de eerder genoemde formule.
Stap 1: Bereken het rekenkundig gemiddelde
Eerst berekenen we het rekenkundig gemiddelde van de gegevens door deze op te tellen en te delen door het totale aantal gegevens (in dit geval 5):
Rekenkundig gemiddelde (X̄) = (8 + 12 + 6 – 4 + 10) ÷ 5 = $6,4 miljoen
Stap 2: Gebruik de variantieformule
Vervolgens gebruiken we de variantieformule om het kwadraat van de verschillen tussen elk gegevenspunt en het rekenkundig gemiddelde te berekenen, en tellen ze vervolgens bij elkaar op:
Waar x i elk data-element is, is X̄ het rekenkundig gemiddelde en n het totale aantal data-elementen.
We vervangen de gegevens en het rekenkundig gemiddelde in de variantieformule:
Afwijking (Var(X)) = [(8 – 6,4) 2 + (12 – 6,4) 2 + (6 – 6,4) 2 + (-4 – 6,4) 2 + (10 – 6,4) 2 ] ÷ (5 – 1)
Stap 3: Operaties oplossen
Laten we nu de bewerkingen oplossen om de waarde van de variantie te verkrijgen:
Afwijking (Var(X)) = [1,6 2 + 5,6 2 + 0,16 2 + (-10,4) 2 + 3,6 2 ] ÷ 4
Afwijking (Var(X)) = [2,56 + 31,36 + 0,0256 + 108,16 + 12,96] ÷ 4
Afwijking (Var(X)) = 155,072 ÷ 4
Variantie (Var(X)) = 38,768 miljoen kwadraat
De variantie van deze dataset is 38,768 miljoen kwadraat, wat ons een maatstaf geeft voor de spreiding of variabiliteit van de gegevens ten opzichte van het rekenkundig gemiddelde.