Standaard- of standaarddeviatie is een statistische maatstaf die aangeeft hoe ver individuele datapunten verwijderd zijn van het gemiddelde of gemiddelde van een dataset. Het is een maatstaf voor spreiding die wordt gebruikt om te begrijpen hoeveel de gegevens afwijken van het ensemblegemiddelde.
In complexere termen is de standaard of standaarddeviatie de vierkantswortel van de variantie . De variantie wordt berekend als het gemiddelde van de gekwadrateerde verschillen tussen elk gegevensitem en het algemene gemiddelde. Door de wortel van de variantie te nemen, ontstaat de standaarddeviatie, die in dezelfde eenheden ligt als de oorspronkelijke gegevens.
Het is vermeldenswaard dat dit een belangrijke maatstaf is in de statistiek. Dankzij dit is het mogelijk om de spreiding van de gegevens te kwantificeren en te begrijpen hoe deze is verdeeld in vergelijking met het gemiddelde. Een lage standaarddeviatie geeft aan dat de gegevens dicht bij het gemiddelde liggen. Aan de andere kant geeft een hoge standaarddeviatie aan dat de gegevens meer verspreid zijn of ver van het gemiddelde verwijderd zijn.
Over het algemeen wordt standaarddeviatie gebruikt om de variabiliteit van gegevens in een set te begrijpen en om vergelijkingen te maken.
Waar wordt de standaarddeviatie voor gebruikt?
Standaarddeviatie is een statistisch hulpmiddel dat verschillende toepassingen heeft bij data-analyse. Enkele van de meest bekende hulpprogramma’s zijn:
- Maatstaf voor spreiding : kwantificeert hoe ver individuele gegevens verwijderd zijn van het gemiddelde of het gemiddelde van het geheel. Een hoge standaardafwijking duidt op een grotere spreiding of variabiliteit in de gegevens, terwijl een lage standaardafwijking duidt op minder spreiding.
- Vergelijking van datasets – Kan worden gebruikt om de variabiliteit tussen verschillende datasets te vergelijken. Een set met een grotere standaarddeviatie zal meer verspreide gegevens hebben dan een set met een kleinere standaarddeviatie.
- Identificatie van uitschieters – Dit kan ook helpen bij het identificeren van uitschieters of extremen in een dataset. Als een datapunt meerdere standaarddeviaties van het gemiddelde afwijkt, kan dit erop duiden dat het een ongebruikelijke of uitschieterwaarde is.
- De nauwkeurigheid van een model evalueren – In sommige gevallen wordt standaardafwijking gebruikt als maatstaf voor de nauwkeurigheid van een model of schatting. In inferentiële statistieken kan de standaarddeviatie bijvoorbeeld worden gebruikt om betrouwbaarheidsintervallen te berekenen of om hypothesetests uit te voeren.
Eigenschappen van standaarddeviatie
Standaarddeviatie heeft verschillende belangrijke eigenschappen die het vermelden waard zijn:
- Standaardafwijking is een maat voor afstand, dus het is altijd een niet-negatieve waarde .
- Als alle gegevens in de set dezelfde waarde hebben, is de standaardafwijking nul .
- Het wordt beïnvloed door uitbijters en kan aanzienlijk worden beïnvloed in de dataset.
- Het is gevoelig voor de schaal van de gegevens . Als de gegevens grootschalig zijn, zal de standaarddeviatie ook groot zijn, en omgekeerd.
- Dit is een maatstaf voor de relatieve spreiding , aangezien deze wordt uitgedrukt in dezelfde eenheden als de oorspronkelijke gegevens.
Wat is de formule voor standaarddeviatie?
De wiskundige formule voor standaarddeviatie is:
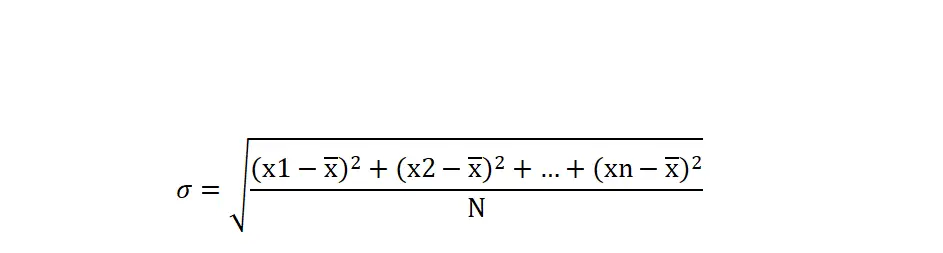
Goud:
σ: vertegenwoordigt de standaardafwijking.
Σ: Geeft de som aan.
xi: Dit zijn de individuele waarden van de dataset.
Gemiddelde: Dit is het gemiddelde of gemiddelde van de dataset.
n is het totale aantal gegevens in de set.
Standaarddeviatie is een spreidingsmaatstaf die ons in staat stelt te begrijpen hoeveel de gegevens in een set verschillen van het gemiddelde of gemiddelde. Het wordt verkregen door de wortel te berekenen van de som van de kwadraten van de verschillen tussen elke waarde in de set en het gemiddelde van de set, gedeeld door het totale aantal gegevens in de set.
Hoe wordt de standaardafwijking berekend?
De standaardafwijking wordt berekend met behulp van de volgende stappen:
1. Bereken het gemiddelde of gemiddelde van de dataset
Het gemiddelde wordt verkregen door alle waarden in de dataset bij elkaar op te tellen en het resultaat te delen door de totale datawaarde. Wiskundig wordt dit uitgedrukt door:
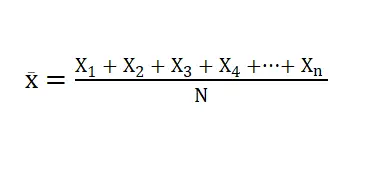
Waar xi elk van de waarden in de dataset is, is n het aantal data-items in de set en vertegenwoordigt Σ de som.
2. Trek het gemiddelde af van elk van de waarden in de dataset
Om de verschillen tussen elke waarde in de dataset en het gemiddelde te verkrijgen, wordt het gemiddelde (berekend in de vorige stap) afgetrokken van elk van de waarden in de dataset. Hierdoor kunnen we vaststellen hoe ver de gegevens van het gemiddelde afwijken.
3. Vier elk van de verschillen die je in de vorige stap hebt verkregen
De in de vorige stap verkregen verschillen worden gekwadrateerd. Deze stap wordt uitgevoerd om te voorkomen dat positieve en negatieve verschillen elkaar opheffen en om de waarden te benadrukken die het verst van het gemiddelde verwijderd zijn.
4. Bereken het gemiddelde van de waarden verkregen in de vorige stap
Het gemiddelde van de waarden verkregen in de vorige stap wordt berekend. Dit gemiddelde vertegenwoordigt de som van de kwadraten van de verschillen gedeeld door het totale aantal gegevens. Wiskundig wordt dit uitgedrukt door:
Gemiddelde kwadratische verschillen = Σ((xi – gemiddelde)²) ÷ n
5. Bereken de vierkantswortel van de waarde die u in de vorige stap hebt verkregen
De laatste stap is het verkrijgen van de vierkantswortel van de waarde die in de vorige stap is verkregen. Dit levert de standaarddeviatie op, die een maatstaf is voor de spreiding van de gegevens ten opzichte van het gemiddelde.
Hoe wordt de standaarddeviatie geïnterpreteerd?
Het is belangrijk op te merken dat de interpretatie van de standaarddeviatie afhangt van de context en de aard van de bestudeerde gegevens .
Daarom is het essentieel om de betekenis van standaarddeviatie volledig te begrijpen en deze te gebruiken in combinatie met andere statistische metingen om een volledig en nauwkeurig inzicht te krijgen in de variabiliteit van gegevens. Laten we hieronder enkele voorbeelden bekijken.
Variabiliteitsanalyse
De standaarddeviatie wordt gebruikt om de variabiliteit of spreiding van gegevens in een set te beoordelen . Als de standaarddeviatie laag is, geeft dit aan dat de gegevens dicht bij het gemiddelde liggen en weinig variabiliteit hebben. Aan de andere kant, als de standaarddeviatie hoog is, geeft dit aan dat de gegevens meer verspreid zijn en een grotere variabiliteit hebben.
gegevensvergelijking
Het is nuttig voor het vergelijken van de variabiliteit tussen verschillende datasets . Als bijvoorbeeld de standaarddeviatie van het inkomen van twee landen wordt vergeleken, kan worden afgeleid welk land een grotere variabiliteit heeft in het inkomen van de bevolking.
Uitschieters identificeren
Helpt bij het identificeren van uitschieters of ongebruikelijke gegevens in een set . Gegevens die meer dan één of twee standaarddeviaties van het gemiddelde afwijken, kunnen als uitbijters worden beschouwd.
Evaluatie van de meetnauwkeurigheid
Het wordt ook gebruikt als maatstaf voor de nauwkeurigheid of betrouwbaarheid van een meting of schatting . Als u bijvoorbeeld onderzoek doet en metingen krijgt met een hoge standaarddeviatie, kan dit erop wijzen dat de metingen minder nauwkeurig zijn en dat er meer zorg moet worden besteed aan het verzamelen van de gegevens.
Beoordeling van de normaliteit van gegevens
De standaarddeviatie wordt gebruikt in combinatie met andere maatstaven om te beoordelen of de gegevens een normale verdeling volgen . Als de gegevens een kleine standaardafwijking van het gemiddelde hebben, kan dit erop duiden dat de gegevens ongeveer volgens een normale verdeling zijn verdeeld.
Numerieke voorbeelden van standaardafwijking
Hoewel het waar is dat het over het algemeen complex kan zijn, wordt de standaarddeviatie op een eenvoudige manier begrepen. Om twijfels te verhelderen, delen we hieronder enkele voorbeelden, waarbij we twee verschillende methoden gebruiken.
vierkantswortel van variantie
Stel dat we de volgende gegevens hebben: 9, 3, 8, 9 en 16.
Stap 1: Bereken het rekenkundig gemiddelde:
Rekenkundig gemiddelde = (9 + 3 + 8 + 9 + 16) ÷ 5 = 9.
Stap 2: Pas de variantieformule toe:
Afwijking = [(9 – 9) 2 + (3 – 9) 2 + (8 – 9) 2 + (9 – 9) 2 + (16 – 9) 2 ] ÷ 5 = 86 ÷ 5 = 17,2.
Stap 3: Neem de vierkantswortel van de variantie:
Standaardafwijking = √(17,2) ≈ 4,14.
Som van afwijkingen en delen door totaal aantal waarnemingen
Stel dat we de volgende gegevens hebben: 2, 4, 2, 4, 2 en 4.
Stap 1: Bereken het rekenkundig gemiddelde:
Rekenkundig gemiddelde = (2 + 4 + 2 + 4 + 2 + 4) ÷ 6 = 3.
Stap 2: Bereken de standaardafwijking door de afwijkingen bij elkaar op te tellen en te delen door het totale aantal waarnemingen:
Standaardafwijking = [(2 – 3) + (4 – 3) + (2 – 3) + (4 – 3) + (2 – 3) + (4 – 3)] ÷ 6 = (1 + 1 + 1 + 1 + 1 + 1) ÷ 6 = 1.
In beide gevallen verkrijgen we met verschillende rekenmethoden een standaarddeviatie van respectievelijk ongeveer 4,14 en 1. Dit illustreert hoe de standaardafwijking kan worden verkregen door de vierkantswortel van de variantie te gebruiken of door de afwijkingen op te tellen en te delen door het totale aantal waarnemingen.