分散は、データが平均の周囲にどの程度適切に分布しているかを示す統計的尺度です。平均値からデータがどの程度「広がり」ているかを測定するようなものです。
テストの点数などの数字のリストがあると想像してください。分散は、これらのスコアが互いにどのように異なるかを理解するのに役立ちます。スコアが互いに非常に近い場合、分散は低くなります。ただし、スコア間に大きな差がある場合、分散は大きくなります。
一般に、分散は、一連の値におけるデータの分散を理解するのに役立つツールです。分散が高い場合はデータがより分散していることを意味し、分散が低い場合はデータが互いに接近していることを意味します。
ギャップはどのように計算されますか?
分散を計算するには、いくつかの数学的手順を実行する必要がありますが、見た目よりも簡単なので心配しないでください。まず、データの平均を計算する必要があります。次に、平均から各データを引き、それぞれの差を二乗します。次に、これらの正方形をすべて加算し、データ量で割ります。それは偏差値です。
これをもう少しよく理解するために、以下の分散の計算例を見てみましょう。
ステップ 1: データを取得する
次のデータがあるとします: 5、7、9、11、13。これらは、分散を計算するデータのサンプルからの値です。
ステップ 2: 平均を計算する
すべての値を合計し、データの総量で割って平均を取得します。
平均 = (5 + 7 + 9 + 11 + 13) ÷ 5 = 45 ÷ 5 = 9
データの平均は 9 です。
ステップ 3: 各データポイントから平均を減算する
前のステップで取得した平均をリスト内の各データ項目から減算します。
5 – 9 = -4
7 – 9 = -2
9 – 9 = 0
11 – 9 = 2
13 – 9 = 4
ステップ 4: それぞれの差を二乗する
前のステップで得られた各差を二乗します。
(-4) 2 = 16
(-2) 2 = 4
0 2 = 0
2 2 = 4
4 2 = 16
ステップ 5: 差の二乗を加算する
前のステップで得られたすべての結果を合計します。
16 + 4 + 0 + 4 + 16 = 40
ステップ 6: データ量で割る
差の二乗和をデータの総量 (この場合は 5) で割ります。
偏差 = 40 ÷ 5 = 8
データの分散は 8 です。
分散の公式は何ですか?
この点を分析する前に、分散は統計にとって非常に重要であることに言及することが重要です。これは非常に単純な測定であるという事実にもかかわらず、特定の変数に基づいて興味深い情報を提供します。
測定単位は常にデータに対応する 2 乗になります。さらに、分散は常にゼロ以上であることに注意してください。これは、残差が常に 2 乗されるため、数学的に言えば、負の分散が存在することは不可能であるためです。
これを念頭に置いて、以下に分散の公式を示します。
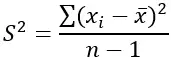
S2 = ギャップ
x i = データセット項
X̄ = サンプル測定値
∑ = 合計
n = サンプルサイズ
高分散と低分散とは何ですか?
統計サンプルまたは母集団のデータがまれで平均からかけ離れている場合、分散は高いと見なされます。これは、データ内の個々の値が広く分布しており、データに大きなばらつきがあることを意味します。
対照的に、サンプルまたは母集団のデータが平均に近く、個々の値間の分散がほとんどない場合、分散は低いとみなされます。これは、データの一貫性がより高く、ばらつきが少ないことを意味します。
分散の主な用途は何ですか?
分散は、サンプル内のデータの分散または変動性を評価できるため、さまざまな分野で広く使用されている統計的尺度です。分散の主な用途には次のようなものがあります。
記述統計– サンプル内のデータの分散を記述し、個々の値が平均からどのように逸脱しているか、サンプル内でどのように分布しているかを理解するのに役立ちます。
推論統計– サンプルから母集団内のデータのばらつきを推定し、母集団全体について推論できるようにします。
金融分野: 投資のリスクとリターンの分析。分散が大きいほどリスクが高いことを示し、分散が小さいほど投資ポートフォリオのリスクが低いことを示します。
科学研究– 医学研究、生物学、心理学、その他の分野などの科学研究におけるデータのばらつきを分析し、結果のばらつきとデータの一貫性を理解します。
プロセス品質の管理: 工業プロセスの品質管理では、製造される製品またはサービスのばらつきを測定し、プロセスの一貫性と品質の問題を特定することができます。
計量経済学: 経済変数の変動性を理解し、計量経済モデルの信頼性を評価するための経済データのモデリングと分析。
差異の意味は何ですか?
分散はサンプル内のデータのばらつきを理解できるため重要です。分散が大きい場合は、データがまばらで、ばらつきが大きいことを意味します。これは、投資、リスク管理、データ分析などの分野で情報に基づいた意思決定を行うことに関連します。
さらに、分散はサンプルまたは母集団内のデータの一貫性を理解するのに役立ちます。低い分散は、データに一貫性があり、変動がほとんどないことを示します。一方、高い分散は、データの一貫性が低く、変動が大きいことを示します。
標準偏差と分散は同じですか?
標準偏差と分散は、サンプルまたは母集団内のデータの広がりまたは変動性を表す2 つの関連する統計的尺度です。それらの主な違いは、測定単位と結果の解釈です。
分散は、平均からのデータの分散を表す尺度であり、平均からの個々の値の偏差の二乗和をデータの総数で割って計算されます。
これは、各値と平均の差を二乗して合計し、サンプルまたは母集団のサイズで割ることによって計算されます。分散は二乗単位で表され、元のデータとはスケールが異なるため、直接解釈するのが難しい場合があります。
一方、標準偏差は分散の平方根にすぎません。これは、分散の正の平方根として計算されます。標準偏差は元のデータと同じ単位で表され、データの分散をより直観的に測定する尺度です。
標準偏差が高いほど、データの広がりまたはばらつきが大きいことを示し、標準偏差が低いほど、広がりまたはばらつきが小さいことを示します。
グループ化されたデータのギャップ
グループ化されたデータの分散とは、間隔またはクラスにグループ化されたデータの変動性または分散の計算を指します。グループ化されていないデータの分散の場合のように、個々のデータを持つ代わりに、データが該当する範囲または間隔を持ちます。
グループ化されたデータの分散の計算は、少し異なる式を使用して行われます。まず、各間隔の中点が計算されます。これは、各間隔の下限と上限の平均です。次に、間隔の相対頻度または絶対頻度を重みとして使用して、中間点の加重平均が計算されます。
この加重平均から、グループ化されていないデータと同じ式に従って分散が計算されます。つまり、個々の値と加重平均の差の二乗の平均として分散が計算されます。
グループ化されたデータ分散は、人口統計データ、経済データ、またはカテゴリや範囲にグループ化されたその他の種類のデータなど、間隔またはクラスとして表示されるデータ セットを操作する場合に役立ちます。
分散特性
分散は、いくつかの重要な特性を持つ統計的尺度です。分散の主な特性のいくつかは次のとおりです。
- 個々のデータと平均値の差の二乗の平均として定義されるため、常に負ではない値になります。
- 差の二乗であるため、データ内の極端な値または異常値の影響を受けやすくなります。
- これには、単位の 2 乗があり、元のデータと同じ単位の 2 乗であることを意味します。
- 外れ値や極端なデータの影響を受ける可能性があり、データのばらつきを示す確実な尺度ではなくなる可能性があります。
- データが独立していて相互に相関がない場合、2 つのデータ セットの合計の分散は2 つのデータ セットの分散の合計に等しくなります。
逸脱の例
分散の概念とその重要性を理解したところで、それがどのように機能するかをより深く理解するために実際の例を見てみましょう。
過去 5 年間の企業の経済的成果について、8、12、6、-4、10 というデータが数百万ドルあるとします。前述の式を使用して、このデータセットの分散を計算したいとします。
ステップ 1: 算術平均を計算する
まず、データを加算し、データの総数 (この場合は 5) で割ることにより、データの算術平均を計算します。
算術平均 (X̄) = (8 + 12 + 6 – 4 + 10) ÷ 5 = 640 万ドル
ステップ 2: 分散公式を使用する
次に、分散公式を使用して各データ ポイントと算術平均の差の 2 乗を計算し、それらを加算します。
ここで、x iは各データ要素、X̄ は算術平均、n はデータ要素の総数です。
データと算術平均を分散公式に代入します。
偏差 (Var(X)) = [(8 – 6.4) 2 + (12 – 6.4) 2 + (6 – 6.4) 2 + (-4 – 6.4) 2 + (10 – 6,4) 2 ] ÷ (5 – 1)
ステップ 3: 演算を解決する
次に、分散の値を取得する演算を解いてみましょう。
偏差 (Var(X)) = [1.6 2 + 5.6 2 + 0.16 2 + (-10.4) 2 + 3.6 2 ] ÷ 4
偏差 (Var(X)) = [2.56 + 31.36 + 0.0256 + 108.16 + 12.96] ÷ 4
偏差 (Var(X)) = 155.072 ÷ 4
分散 (Var(X)) = 3876.8 万 2 乗
このデータセットの分散は 3,876 万 8,000 乗で、算術平均に対するデータの分散または変動性の尺度が得られます。