Varianz ist ein statistisches Maß, das uns sagt , wie gut Daten um den Mittelwert verteilt sind . Es ist, als würde man messen, wie weit die Daten vom Durchschnittswert „streuen“.
Stellen Sie sich vor, Sie haben eine Liste mit Zahlen, etwa die Ergebnisse eines Tests. Mithilfe der Varianz können Sie verstehen , wie unterschiedlich diese Ergebnisse voneinander sind . Liegen die Werte sehr nahe beieinander, ist die Varianz gering. Wenn es jedoch große Unterschiede zwischen den Werten gibt, ist die Varianz hoch.
Im Allgemeinen ist Varianz ein nützliches Werkzeug zum Verständnis derStreuung von Daten in einer Reihe von Werten. Wenn die Varianz hoch ist, bedeutet dies, dass die Daten weiter verteilt sind, während eine niedrige Varianz bedeutet, dass die Daten näher beieinander liegen.
Wie wird die Lücke berechnet?
Um die Varianz zu berechnen, müssen Sie ein paar mathematische Schritte unternehmen, aber keine Sorge, es ist einfacher als es aussieht. Zuerst müssen Sie den Mittelwert oder Durchschnitt der Daten berechnen. Subtrahieren Sie dann alle Daten vom Mittelwert und quadrieren Sie jede Differenz. Dann addieren Sie alle diese Quadrate und dividieren durch die Datenmenge. Es ist die Varianz.
Um dies etwas besser zu verstehen, sehen wir uns unten ein Beispiel für die Berechnung der Varianz an:
Schritt 1: Holen Sie sich die Daten
Angenommen, Sie haben die folgenden Daten: 5, 7, 9, 11, 13. Dies sind die Werte aus einer Datenstichprobe, für die Sie die Varianz berechnen möchten.
Schritt 2: Berechnen Sie den Durchschnitt
Addieren Sie alle Werte und dividieren Sie sie durch die Gesamtdatenmenge, um den Durchschnitt zu erhalten:
Durchschnitt = (5 + 7 + 9 + 11 + 13) ÷ 5 = 45 ÷ 5 = 9
Der Durchschnitt der Daten beträgt 9.
Schritt 3: Subtrahieren Sie den Mittelwert von jedem Datenpunkt
Subtrahieren Sie den im vorherigen Schritt erhaltenen Durchschnitt von jedem Datenelement in der Liste:
5 – 9 = -4
7 – 9 = -2
9 – 9 = 0
11 – 9 = 2
13 – 9 = 4
Schritt 4: Quadrieren Sie jeden Unterschied
Quadrieren Sie jede der im vorherigen Schritt erhaltenen Differenzen:
(-4) 2 = 16
(-2) 2 = 4
0 2 = 0
2 2 = 4
4 2 = 16
Schritt 5: Addieren Sie die Quadrate der Differenzen
Addieren Sie alle im vorherigen Schritt erhaltenen Ergebnisse:
16 + 4 + 0 + 4 + 16 = 40
Schritt 6: Teilen Sie durch die Datenmenge
Teilen Sie die Summe der Quadrate der Differenzen durch die Gesamtdatenmenge (in diesem Fall 5):
Abweichung = 40 ÷ 5 = 8
Die Varianz der Daten beträgt 8 .
Wie lautet die Varianzformel?
Bevor wir diesen Punkt analysieren, ist es wichtig zu erwähnen, dass die Varianz für die Statistik von großer Bedeutung ist. Obwohl es sich um ein relativ einfaches Maß handelt, liefert es interessante Informationen auf der Grundlage einer bestimmten Variablen.
Die Maßeinheit ist immer diejenige, die den Daten entspricht, jedoch quadriert. Darüber hinaus ist zu beachten, dass die Varianz immer gleich oder größer Null ist. Dies liegt daran, dass die Residuen immer quadriert werden, sodass es mathematisch gesehen unmöglich ist, dass es eine negative Varianz gibt.
Vor diesem Hintergrund zeigen wir Ihnen im Folgenden die Varianzformel:
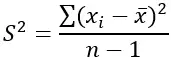
S2 = Lücke
x i = Datensatzterm
X̄ = Probenmessung
∑ = Summe
n = Stichprobengröße
Was ist hohe und niedrige Varianz?
Die Varianz gilt als hoch, wenn die Daten in einer statistischen Stichprobe oder Population selten sind und weit vom Mittelwert entfernt sind. Dies bedeutet, dass einzelne Werte in den Daten weit verbreitet sind und eine große Variabilität in den Daten vorliegt.
Im Gegensatz dazu gilt die Varianz als gering, wenn die Daten in einer Stichprobe oder Grundgesamtheit näher am Mittelwert liegen und die Streuung zwischen einzelnen Werten gering ist . Dies bedeutet, dass die Daten konsistenter sind und weniger Schwankungen aufweisen.
Was sind die Hauptverwendungszwecke der Varianz?
Varianz ist ein statistisches Maß, das in verschiedenen Bereichen häufig verwendet wird, da es die Streuung oder Variabilität von Daten in einer Stichprobe beurteilen kann. Einige der Hauptverwendungszwecke der Varianz sind:
In der deskriptiven Statistik – um die Streuung von Daten in einer Stichprobe zu beschreiben und zu verstehen, wie einzelne Werte vom Mittelwert abweichen und wie sie innerhalb der Stichprobe verteilt sind.
In der Inferenzstatistik – zur Schätzung der Variabilität von Daten in einer Grundgesamtheit anhand einer Stichprobe, wodurch Rückschlüsse auf die Grundgesamtheit als Ganzes gezogen werden können.
Im Finanzwesen : bei der Analyse von Anlagerisiko und -rendite, wobei eine höhere Varianz auf ein höheres Risiko und eine geringere Varianz auf ein geringeres Risiko in einem Anlageportfolio hinweist.
In der wissenschaftlichen Forschung – Analysieren Sie die Variabilität von Daten in wissenschaftlichen Studien, beispielsweise in der medizinischen Forschung, Biologie, Psychologie und anderen Disziplinen, um die Variabilität der Ergebnisse und die Konsistenz der Daten zu verstehen.
Bei der Kontrolle der Prozessqualität : Bei der Qualitätskontrolle industrieller Prozesse zur Messung der Variabilität der hergestellten Produkte oder Dienstleistungen, die es ermöglicht, Probleme der Konsistenz und Qualität des Prozesses zu identifizieren.
In der Ökonometrie : in der Modellierung und Analyse von Wirtschaftsdaten, um die Variabilität wirtschaftlicher Variablen zu verstehen und die Zuverlässigkeit ökonometrischer Modelle zu bewerten.
Was bedeutet Varianz?
Varianz ist wichtig, weil sie es Ihnen ermöglicht , die Variabilität von Daten in einer Stichprobe zu verstehen . Wenn die Varianz hoch ist, bedeutet dies, dass die Daten spärlich sind und eine große Variabilität besteht. Dies ist relevant für fundierte Entscheidungen in Bereichen wie Investitionen, Risikomanagement und Datenanalyse.
Darüber hinaus hilft Ihnen die Varianz, die Konsistenz von Daten in einer Stichprobe oder Grundgesamtheit zu verstehen. Eine niedrige Varianz bedeutet, dass die Daten konsistent sind und eine geringe Variabilität aufweisen, während eine hohe Varianz darauf hinweist, dass die Daten weniger konsistent sind und eine größere Variabilität aufweisen.
Sind Standardabweichung und Varianz gleich?
Standardabweichung und Varianz sind zwei verwandte statistische Maße, die die Streuung oder Variabilität von Daten in einer Stichprobe oder Population beschreiben . Der Hauptunterschied zwischen ihnen besteht in der Maßeinheit und der Interpretation der Ergebnisse.
Varianz ist ein Maß, das die Streuung der Daten von ihrem Mittelwert darstellt und als Summe der Quadrate der Abweichungen einzelner Werte vom Mittelwert geteilt durch die Gesamtzahl der Daten berechnet wird.
Er wird berechnet, indem die Differenzen zwischen jedem Wert und dem Mittelwert quadriert, addiert und durch die Stichproben- oder Populationsgröße dividiert werden. Die Varianz wird in quadrierten Einheiten ausgedrückt und kann schwer direkt zu interpretieren sein, da sie sich auf einer anderen Skala als die Originaldaten befindet.
Andererseits ist die Standardabweichung nichts anderes als die Quadratwurzel der Varianz . Sie wird als positive Quadratwurzel der Varianz berechnet. Die Standardabweichung wird in denselben Einheiten wie die Originaldaten ausgedrückt und ist ein intuitiveres Maß für die Datenstreuung.
Eine höhere Standardabweichung weist auf eine größere Streuung oder Variabilität der Daten hin, während eine niedrigere Standardabweichung auf eine geringere Streuung oder Variabilität hinweist.
Lücke für gruppierte Daten
Unter Varianz für gruppierte Daten versteht man die Berechnung der Variabilität oder Streuung von Daten, die in Intervallen oder Klassen gruppiert sind . Anstelle einzelner Daten, wie im Fall der Varianz für nicht gruppierte Daten, gibt es Bereiche oder Intervalle, in die die Daten fallen.
Die Berechnung der Varianz für gruppierte Daten erfolgt mit einer etwas anderen Formel. Zunächst wird der Mittelpunkt jedes Intervalls berechnet, der der Durchschnitt der unteren und oberen Grenzen jedes Intervalls ist. Dann wird der gewichtete Durchschnitt der Mittelpunkte berechnet, wobei die relativen oder absoluten Häufigkeiten der Intervalle als Gewichte verwendet werden.
Aus diesem gewichteten Durchschnitt wird die Varianz nach der gleichen Formel wie bei ungruppierten Daten berechnet, also als Durchschnitt der Quadrate der Differenzen der Einzelwerte und des gewichteten Durchschnitts.
Die Varianz gruppierter Daten ist nützlich, wenn Sie mit Datensätzen arbeiten, die als Intervalle oder Klassen dargestellt werden , z. B. demografische Daten, Wirtschaftsdaten oder jede andere Art von Daten, die in Kategorien oder Bereiche gruppiert sind.
Varianzeigenschaften
Varianz ist ein statistisches Maß, das mehrere wichtige Eigenschaften hat. Einige der Haupteigenschaften der Varianz sind:
- Es handelt sich immer um einen nicht negativen Wert , da er als Mittelwert der Quadrate der Differenzen zwischen den einzelnen Daten und dem Mittelwert definiert ist.
- Es reagiert empfindlich auf extreme oder Ausreißerwerte in den Daten , da es sich um das Quadrat der Differenzen handelt.
- Es hat Einheiten im Quadrat , was bedeutet, dass es sich um dieselbe Einheit im Quadrat handelt wie die Originaldaten.
- Es kann durch Ausreißer oder extreme Daten beeinflusst werden, was es zu einem nicht robusten Maß für die Datenvariabilität machen kann.
- Wenn die Daten unabhängig und nicht miteinander korreliert sind, ist die Varianz der Summe zweier Datensätze gleich der Summe der Varianzen der beiden Datensätze .
Beispiele für Abweichungen
Nachdem wir nun das Konzept der Varianz und seine Bedeutung verstanden haben, schauen wir uns ein praktisches Beispiel an, um besser zu verstehen, wie es funktioniert.
Angenommen, wir haben die folgenden Daten zum wirtschaftlichen Ergebnis eines Unternehmens in Millionen Dollar für die letzten fünf Jahre: 8, 12, 6, -4, 10. Wir möchten die Varianz dieses Datensatzes mithilfe der zuvor genannten Formel berechnen.
Schritt 1: Berechnen Sie das arithmetische Mittel
Zuerst berechnen wir das arithmetische Mittel der Daten, indem wir es addieren und durch die Gesamtzahl der Daten dividieren (in diesem Fall 5):
Arithmetisches Mittel (X̄) = (8 + 12 + 6 – 4 + 10) ÷ 5 = 6,4 Millionen US-Dollar
Schritt 2: Verwenden Sie die Varianzformel
Als nächstes verwenden wir die Varianzformel, um das Quadrat der Differenzen zwischen jedem Datenpunkt und dem arithmetischen Mittel zu berechnen, und addieren sie dann:
Dabei ist x i jedes Datenelement, X̄ das arithmetische Mittel und n die Gesamtzahl der Datenelemente.
Wir setzen die Daten und das arithmetische Mittel in die Varianzformel ein:
Abweichung (Var(X)) = [(8 – 6,4) 2 + (12 – 6,4) 2 + (6 – 6,4) 2 + (-4 – 6,4) 2 + (10 – 6,4) 2 ] ÷ (5 – 1)
Schritt 3: Operationen lösen
Lösen wir nun die Operationen, um den Wert der Varianz zu erhalten:
Abweichung (Var(X)) = [1,6 2 + 5,6 2 + 0,16 2 + (-10,4) 2 + 3,6 2 ] ÷ 4
Abweichung (Var(X)) = [2,56 + 31,36 + 0,0256 + 108,16 + 12,96] ÷ 4
Abweichung (Var(X)) = 155,072 ÷ 4
Varianz (Var(X)) = 38,768 Millionen im Quadrat
Die Varianz dieses Datensatzes beträgt 38,768 Millionen Quadrat, was uns ein Maß für die Streuung oder Variabilität der Daten relativ zum arithmetischen Mittel gibt.